CloudFlare D1 数据库使用文档
相关文档:
简要步骤(cli 方式)如下:
- 初始化项目-创建 worker
- 进入项目-创建 database
- 绑定 worker 到 database
- 创建表、查询表、通过 worker 访问数据库
- 开发|部署|删除 数据库
这些步骤都在官方文档中写的清清楚楚,而针对 worker 和 database 的关系是多对多。
worker 访问多个 database 的话,需要将多个 database 的 id 和 name 填入到 wrangler.toml 文件中。
而一个 database 可以被多个 worker 访问。只要在别的 worker 中也绑定相同的 database 即可。
1. 创建 worker
pnpm create cloudflare@latest d1-tutorial
先按照 CloudFlare D1 初始化 文档创建一个数据库。
2. 创建 database
cd d1-tutorial
npx wrangler d1 create prod-d1-tutorial
这里的 prod-d1-tutorial 是数据库的名称,可以自定义。在执行完 create 命令后,会显示出数据库的 name 和 id。
3. 绑定 worker 到 database
将上面获取到的 name 和 id 填入到 wrangler.toml 文件中。
[[d1_databases]]
binding = "DB"
database_name = "prod-d1-tutorial"
database_id = "xxxxx"
记得别忘记 [[d1_databases]] 这一行。
而这里的 binding 就是在 worker 中访问数据库的名称。
然后执行一下:npm run cf-typegen ,这会将 wrangler.toml 中的数据库信息生成到 worker-configuration.d.ts 文件中。
那这样,上面的 DB 可以理解为外键,在 worker 中也就可以通过 DB 来访问数据库。
4. 创建表、查询表、通过 worker 访问数据库
上一步绑定成功后,这一步直接按照官方文档走,不会有任何问题。
修改好 /src/index.ts 文件后,可以通过 worker 访问了,执行启动项目:npm run dev ,就可以在浏览器中访问到 worker 执行查询了。
- 创建表:
DROP TABLE IF EXISTS Customers;
CREATE TABLE
IF NOT EXISTS Customers (
CustomerId INTEGER PRIMARY KEY,
CompanyName TEXT,
ContactName TEXT
);
INSERT INTO
Customers (CustomerID, CompanyName, ContactName)
VALUES
(1, 'Alfreds Futterkiste', 'Maria Anders'),
(4, 'Around the Horn', 'Thomas Hardy'),
(11, 'Bs Beverages', 'Victoria Ashworth'),
(13, 'Bs Beverages', 'Random Name');
- 写入到本地开发数据库中:
npx wrangler d1 execute prod-d1-tutorial --local --file schema.sql
- 执行查询:
npx wrangler d1 execute prod-d1-tutorial --remote --command="SELECT * FROM Customers"
- 写入
src/index.ts文件,运行项目并访问:
export default {
async fetch(request, env: Env): Promise<Response> {
const { pathname } = new URL(request.url);
if (pathname === "/api/beverages") {
const { results } = await env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?",
)
.bind("Bs Beverages")
.all();
return Response.json(results);
}
return new Response(
"Call /api/beverages to see everyone who works at Bs Beverages",
);
},
} satisfies ExportedHandler<Env>;
执行命令:
npm run dev
本地开发绑定的地址和端口号: http://localhost:8787/
通过这个地址访问 /api/beverages ,就可以看到查询结果了。
5. 开发|部署|删除 数据库
这里也是,直接照官网文档执行命令就好了。
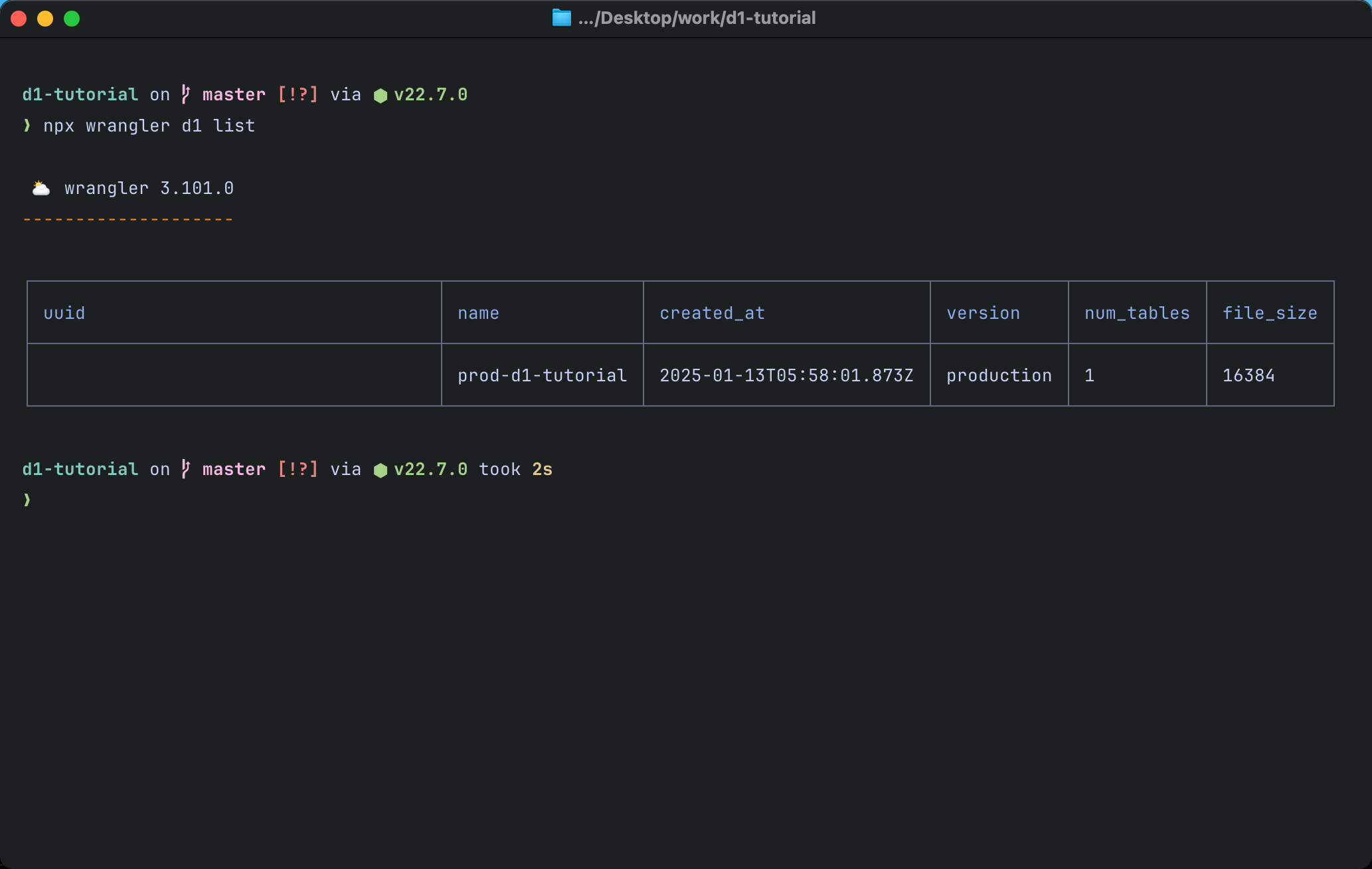
可以通过这个命令查询到当前 worker 绑定的数据库:
npx wrangler d1 list
6. 直接通过 sql 查询数据
上面几条就是官网的步骤,非常简单的就实现了通过 worker 查询数据库,并且发布到了 CloudFlare 上。
但是在开发过程中,可能会需要直接通过 sql 查询数据,而不是先写个 worker 再执行 worker 查询。直接 sql 查询会更方便。
所以还是需要有一个 sql 的文件,然后通过 npx wrangler d1 execute 命令执行。
7. 使用 hono.js 框架分发路由
因为直接单调的使用 fetch 请求,路由会显得很麻烦。 所以这里考虑使用 hono.js 框架,进行路由分发。CloudFlare 也支持 hono.js 框架,文档如下: https://developers.cloudflare.com/d1/examples/d1-and-hono/。
7.1 安装 hono.js 框架
pnpm run install hono
7.2 修改 index.ts 文件
import { Context, Hono } from "hono";
import { Bindings } from "hono/types";
const app = new Hono<{ Bindings: Bindings }>();
app.get('/', (c) => c.text('Hello World'))
app.get("/api/beverages", async (c: Context) => {
try {
let { results } = await c.env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?",
)
.bind("Bs Beverages")
.all();
return c.json(results);
} catch (e: any) {
return c.json({ err: e.message }, 500);
}
})
export default app
7.3 运行项目并访问
npm run dev
访问地址: http://localhost:8787/
页面中会显示hello world
访问 http://localhost:8787/api/beverages ,会看到执行 sql 的查询结果。
7.4 部署项目
npx wrangler deploy
部署成功后,会返回一个 url 地址,访问这个地址,就跟访问本地开发环境一样的结果。
8. 总结
通过上面的步骤,就能创建并使用 CloudFlare D1 数据库了。
但是 CloudFlare 的 D1 数据库并没有修改命令,比如上面我们按照教程创建的名为 prod-d1-tutorial 的数据库,如果想要修改名称,则需要删除再发布。
删除
npx wrangler d1 delete prod-d1-tutorial
发布
npx wrangler deploy
还是能重新发布上去,然后直接用的。